
Con la función “Near Duplicate Content“ sabrás qué contenido de tu web es demasiado similar. ¿Qué diferencia hay entre “Contenido Duplicado“ y “Near Duplicate“? ¿Por qué es tan importante esta función?
Ahora nuestros clientes podrán analizar incluso con más detalle el contenido de sus sitios web. Especialmente útil para los sitios web que fueron penalizados tras la actualización Panda de Google, esta función de análisis del "Near Duplicate Content" os ayudará a identificar contenido demasiado similar y de esta forma evitar posibles penalizaciones.
Para poder ver la diferencia entre estos dos conceptos, os explicaremos brevemente qué significa exactamente “Contenido Duplicado”. En los últimos dos años este término ha sufrido muchos cambios. La primera versión de OnPage.org todavía se basaba en la originalidad de los textos, “Text Uniqueness”: un indicador bastante bueno ya que te ofrecía un porcentaje claro con respecto a la originalidad de tus contenidos, “Unique Content”. El problema era principalmente que no era capaz de analizar un sitio web de, por ejemplo, 1 Millón de URLs. Es decir, este indicador no era capaz de aguantar el ritmo. Por este motivo decidimos buscar una solución...
Por cierto, para este análisis nos centramos solo en el contenido y no en el código. Además, eliminamos los números antes de calcular este valor ya que un mínimo signo podría alterar el valor final. Para analizar dicho contenido, lo que hacemos es centrar nuestro análisis en las Fingerprints de los documentos, es decir sus huellas digitales únicas.
Nosotros utilizamos estos datos para comparar las páginas entre sí mismas. Tan pronto encontramos otra URL con el mismo valor, contenido, informamos al usuario de su existencia a través de nuestro informe de “Contenido Duplicado”. Nosotros comparamos solo las páginas indexables: las páginas que apuntan a otras páginas con una etiqueta Canonical, Robots.txt, Noindex, etc. no son examinadas.

Después de leer nuestra definición de “Contenido Duplicado” puede que te hayas parado a pensar en lo siguiente: un documento con una huella digital, Fingerprint, que presenta un único signo diferente podría considerarse como contenido diferente, pero en realidad la diferencia entre estos dos documentos es tan mínima, que Google podría considerarla como contenido duplicado. Por este motivo hemos estado trabajando para ofrecer una solución más precisa. Lo que anteriormente conocíamos como “Text Uniqueness” ahora lo hemos adaptado a nuestro análisis de contenido muy similar: “Near Duplicate Content”.
Este nuevo algoritmo analiza también las huellas digitales de los documentos, comparándolos en base a los Bit. Esto es lo que nos ayuda a ver las diferencias entre los textos. Uno puede ver de este modo cuántos cambios son necesarios en un texto A para obtener texto B. Hemos estado probando este algoritmo y como vimos que el número de “Falsos Positivos” era muy bajo, decidimos incluir esta nueva función.
Nuestro objetivo es: detectar páginas muy similares que se diferencian en tan solo 2 o 3 frases y que no ofrecen un valor añadido a los usuarios por separado. Un ejemplo sería una página de producto “Adidas Shoe Size 39” y “Adidas Shoe Size 40” - la única diferencia es el tamaño del zapato, pero esta diferencia no cambia nada en el contenido y la definición de este producto.
Este gráfico te muestra el número de “Near Duplicates” encontrados en tu sitio web.

Si seleccionas una visualización más completa (magnifier) encontrarás una lista con información más detallada de “Near Duplicates” incluso más pequeños.
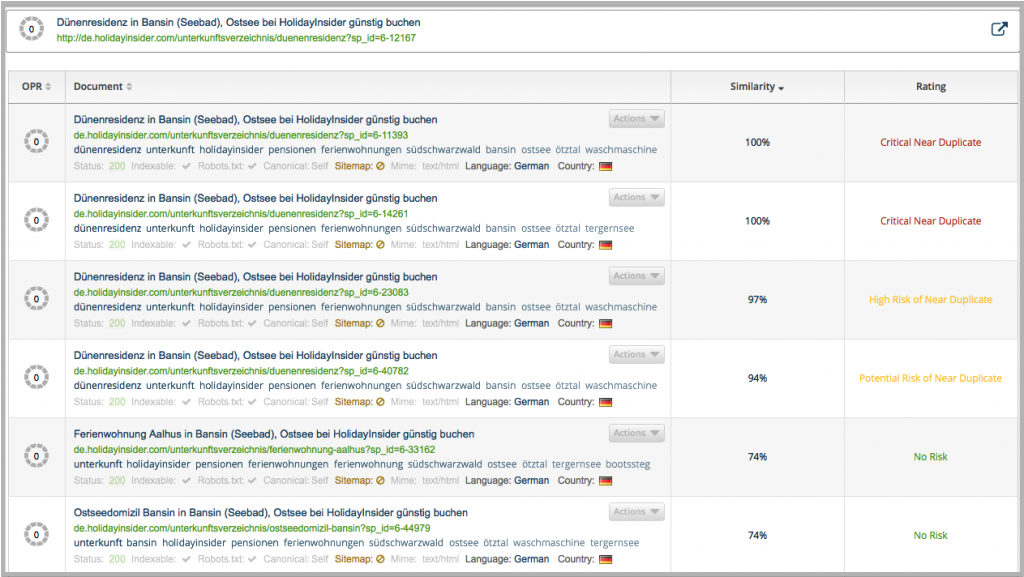
Cualquier persona que esté familiarizada con Google y otros motores de búsqueda sabrá que este tipo de algoritmos son muy importantes: ayudan a los motores de búsqueda a ajustar sus rastreadores. Si un sitio web presenta varias veces un contenido demasiado similar sin ofrecer un valor añadido al usuario, los motores de búsqueda preferirán invertir sus recursos de rastreo en otras partes donde les merezca la pena: donde haya contenido de valor añadido. Por lo tanto, los rastreadores decidirán ignorar estas páginas y todos sus enlaces. Nosotros, por supuesto, no funcionamos de este modo: nuestro objetivo es proporcionarte información detallada sobre todo el contenido de tu sitio web para que puedas mejorarlo y sacarle el mejor partido a su potencial.
Encontrarás nuestra función de análisis de “Near Duplicate Content” en el menú principal de “Contenido” debajo de la categoría “Contenido Duplicado”. Te ayudará a identificar las páginas con demasiadas similitudes de tu sitio web para que puedas adaptarlas a lo que los usuarios y los buscadores quieren: contenido único y de calidad.
¿Te gustaría evitar contenido demasiado similar? Hazlo con tu cuenta gratuita de OnPage.org FREE
Escrito el 14.10.2015 por Alicia Gramage.

Alicia es una trotamundos por naturaleza. Le encanta viajar y empaparse de nuevas culturas mientras disfruta de la gastronomía local. Apasionada de los idiomas y de la comunicación, Alicia decidió emprender una nueva aventura y se mudó a Alemania. Ahora forma parte de Ryte y se encarga del Marketing para España.