
Para cualquier webmaster o responsable de SEO puede ser frustrante vuestro posicionamiento no está mejorando a pesar de tomar grandes medidas de optimización. Pero, es posible que se os haya pasado algo importante. ¿Estás seguro de que Google está indexando tu web?
Aquí es donde Ryte puede ser muy útil: puedes utilizar Ryte como guía paso a paso para encontrar los factores que impiden que tu web se indexe. Una vez que hayas comprobado estos pasos y realizado las correcciones necesarias, nada se interpondrá en el camino para que tu web sea indexada con éxito.
Este es un error que puede ocurrir incluso a los más experimentados SEOs: Puede que hayas insertado accidentalmente la metaetiqueta "noindex, follow" en tus subpáginas, u olvidado eliminarla. Esta etiqueta se utiliza para asegurar que una URL no será indexada por los motores de búsqueda, y se inserta en el area <head> de una página web de la siguiente manera:
<meta name="robots" content="noindex, follow"/>
Esta etiqueta puede ser una forma útil de evitar la duplicación de contenido, y también se puede utilizar, por ejemplo, antes de una transferencia de dominio, para probar el sitio web antes del lanzamiento real. (Aunque cuando tu web entre en funcionamiento, la etiqueta Noindex debería, por supuesto, ser eliminada).
Con Ryte Website Success, puedes comprobar con unos pocos clics qué páginas son indexables. Haz clic en el apartado "Indexabilidad" del informe "URLs indexables".
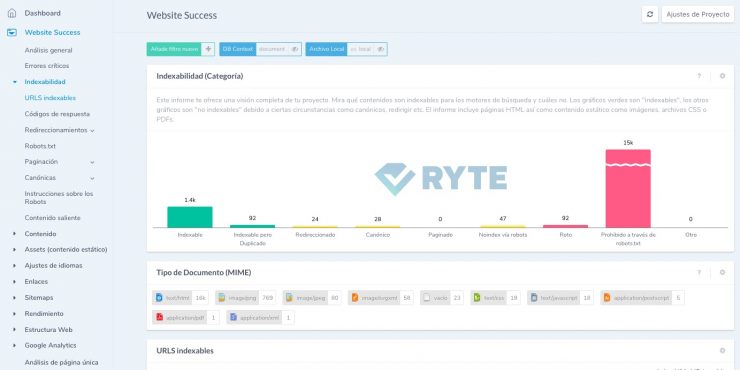
Figura 1: Comprueba tu indexabilidad con Ryte
Con el archivo robots.txt, puedes controlar activamente el crawl y la indexación de tu web dando instrucciones específicas a Googlebot sobre los directorios y las URL que debe rastrear.
Sin embargo, al configurar el archivo, es posible que hayas excluido accidentalmente directorios importantes de la rastreabilidad o que hayas bloqueado páginas enteras. Esto no impide directamente que tus URL se indexen, ya que Googlebot puede encontrarlas, rastrearlas e indexarlas a través de backlinks desde otras webs. Sin embargo, con un archivo robots.txt defectuoso, Googlebot no podrá realizar búsquedas en todas las áreas de tu web con suficiente frecuencia. Lee este artículo para averiguar más errores que se pueden cometer al configurar el archivo robots.txt.
Deberías comprobar el archivo robots.txt en busca de errores, especialmente después de realizar cambios. Ryte puede ayudarte aquí: haz clic en el informe "Robots. txt" en la sección "Indexabilidad". Ryte Website Success te proporcionará una lista de todas las URL excluidas del rastreo. Con Ryte, también puedes supervisar el archivo robots.txt para hacer un seguimiento de cualquier cambio.
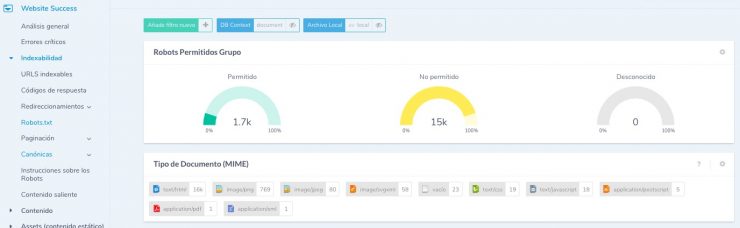
Figura 2: Comprueba tu robots.txt con Ryte
Tu archivo .htaccess también puede impedir que tu página aparezca en los resultados de búsqueda y que se vea rastreada como un acceso no autorizado. El.htaccess es un archivo de control almacenado en un directorio del servidor Apache.
Entre otras cosas, los operadores web las utilizan para las siguientes acciones:
Las reglas concretas se pueden definir en el .htaccess. Sin embargo, para que estas reglas sean ejecutadas por el servidor, el archivo siempre debe tener el mismo nombre en los siguientes casos:
Redireccionamiento o reescritura de URLs:
RewriteEngine On
La reescritura requiere el uso de:
RewriteBase /
Define la regla que el servidor debe ejecutar:
RewriteEngine On
RewriteBase /
RewriteRule seitea.html seiteb.html [R=301]
Por supuesto, es posible que el archivo haya sido nombrado incorrectamente y por lo tanto no pueda reescribir o redirigir URLs. Como resultado, tanto los usuarios como los motores de búsqueda no podrán acceder a las páginas y, por lo tanto, no serán rastreados ni indexados.
Una etiqueta Canónica ayuda a Google a encontrar la URL original para varias URL con el mismo contenido, de modo que se pueda indexar la URL correcta. La etiqueta Canonica hace referencia a una etiqueta HTML con un enlace a la página original, la URL "canónica".
Al configurar las etiquetas canónicas, pueden producirse numerosos errores que causan problemas con la indexación.
Cómo comprobar sus etiquetas canónicas con Ryte:
Ryte tiene su propio informe para etiquetas canónicas en el área "Indexabilidad". Después de hacer clic en "Canónicas" y "Uso" obtendrás rápidamente una visión general de los posibles problemas con tus etiquetas canónicas.
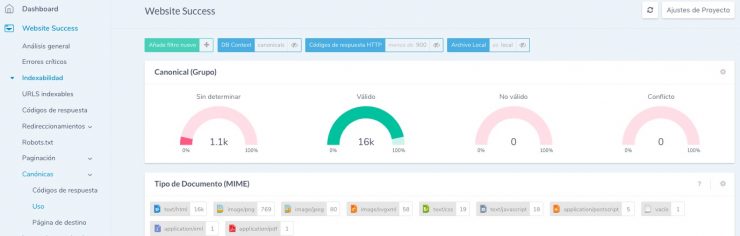
Figura 3: Comprueba etiquetas canónicas con Ryte
Otra razón por la que una web o URL no se puede indexar puede ser debido a un fallo del servidor. Esto hace técnicamente imposible acceder a una página.
Los servidores también juegan un papel importante para la optimización de motores de búsqueda por muchas razones. Para obtener un buen posicionamiento, necesitas un servidor rápido y eficiente. Si es lento, habrá retrasos en el tiempo de carga de tu web que a los usuarios no les gusta, lo que resulta en una alta tasa de rebote y bajo tiempo medio en la página. Google clasifica estos KPIs como negativos para la experiencia del usuario, lo que por supuesto tiene un efecto negativo en el SEO.
Con Ryte Website Success, puedes comprobar regularmente tu servidor; la función de monitorización del servidor te mantiene informado sobre fallos y tiempos de espera para que puedas actuar rápidamente.
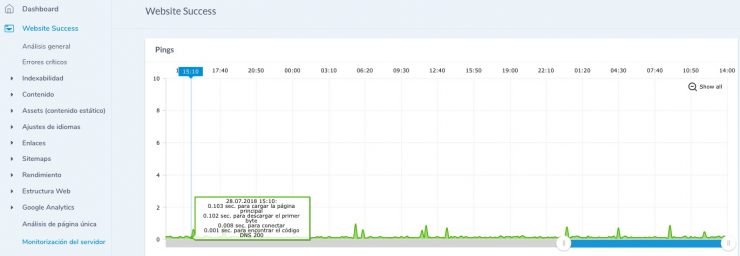
Figura 4: Monitorización del servidor con Ryte
Consejo:
Cuando reestructura tu web, o añades nuevas categorías, es posible que estas nuevas páginas no estén vinculadas internamente. Además, si estas nuevas URLs no están listadas en el sitemap.xml y no están enlazadas desde fuentes externas, existe un alto riesgo de que estas páginas no sean indexadas. Por lo tanto, trata de evitar páginas huérfanas a toda costa.
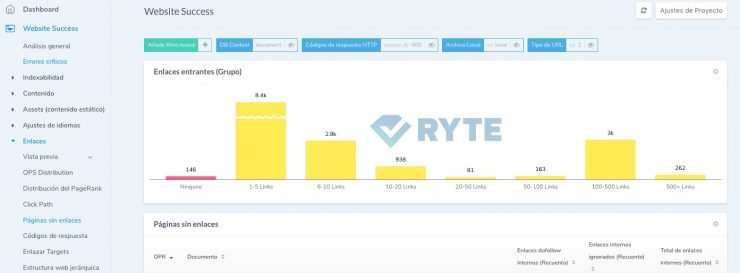
Figura 5: Buscar páginas sin enlaces entrantes
Ryte Website Success te muestra rápidamente las páginas huérfanas. Para ello, haz clic en el informe "Páginas sin enlaces" en la sección "Enlaces".
El contenido duplicado externo significa que una página de Internet externa toma el contenido de tu página. A pesar de que Google ha mejorado el tema de saber cual es el "original", es posible que una página con tu contenido esté mejor posicionada que la tuya, o que, en casos extremos, impide que tu contenido sea indexado.
El siguiente consejo te ayudará a evitar el robo de contenido:
Cuando publiques tu contenido, pide una referencia a la fuente original. Al señalar de antemano las condiciones para la transferencia de estos elementos de texto, se evita la duplicación de contenido externo. Los editores pueden utilizar un aviso específico como "texto original en www.tupaginae.com" o pueden establecer una etiqueta canónica en la URL en la que publicó el contenido originalmente.
Para encontrar contenido duplicado externo, puedes simplemente copiar algunas líneas de texto relevantes de tu página e introducirlas en la barra de búsqueda de Google. Si varios resultados con exactamente el mismo contenido aparecen sin un enlace a tu página, es porque obviamente, se está produciendo un robo de contenido.
Si etiquetas tus enlaces internos con el atributo rel="nofollow", Googlebot no seguirá el enlace y estarás impidiendo el rastreo correcto de tu web, como si impidieras que Googlebot siguiera un enlace, es posible que no pueda llegar a áreas más profundas de la página. Por lo tanto, algunas URLs ya no serán rastreadas, lo que significa que la probabilidad de que sean indexadas disminuye.
Si estás trabajando con enlaces internos nofollow, puedes consultar con Ryte dónde encontrarlos. A continuación, recomendamos que elimines el atributo nofollow. Si realmente deseas excluir una URL de la indexación, la etiqueta noindex en combinación con el atributo "follow" es lo más adecuado.
Al crear un sitemap, es posible que éste no contenga todas las URL que se van a indexar. Esto crea un problema similar a las páginas huérfanas, porque no hay enlaces a las URL en cuestión. Si esto sucede, existe un alto riesgo de no indexación.
Ryte Website Success puede ayudarte con esto. En Website Success, en el área "Sitemap", ve al informe "Código de respuesta de los archivos". Allí se le mostrarán todas las URLs del sitemap que no se encuentran en el servidor o que han sido redirigidas.
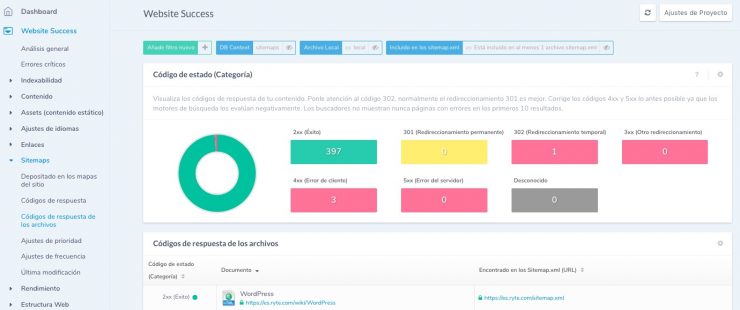
Figura 6: Comprueba tu sitemap.xml para ver si hay errores con Ryte
También puedes comprobar si hay errores en el sitemap con la Google Search Console; un aviso de advertencia indica posibles problemas con la indexación.
Google quiere ofrecer a sus usuarios la mejor calidad posible en los resultados de búsqueda. Las páginas cortadas restringen esta calidad de manera masiva. Asegúrate de buscar pistas en la Google Search Console. Si web ha sido víctima de piratería informática, es el momento de mantener la calma. Si es posible, un primer paso sería cambiar las contraseñas para acceder al backend.
Para evitar los hacks, deberías cambiar las contraseñas regularmente y limitar el número de usuarios de contraseñas tanto como sea posible. Además, es importante que siempre instales todas las actualizaciones ofrecidas. Google ofrece más información y consejos sobre la piratería informática en el blog central para webmasters.
Puede haber muchas razones por las que tu web o URLs individuales no están siendo indexadas. Con Ryte,puedes encontrar y resolver fácilmente los errores, lo que conduce a una mejor indexabilidad de tu web que llevará a un mejor posicionamiento y por tanto, más éxito para tu web.
5Disponibilidad del servidor y registros de códigos de estadoMonitoriza la disponibilidad de tu servidor y comprueba los códigos de estado de tus URL.
| Área | Medida | |
| 1 | Etiquetas Noindex | Comprueba tus URLs para la etiqueta no-index. A menos que esta etiqueta sea completamente necesaria, cámbiala por „index, follow“. |
| 2 | Robots.txt | Comprueba el archivo robots.txt y verifica si los directorios importantes están excluidos del rastreo. |
| 3 | .htaccess | Comprueba si este archivo contiene redirecciones incorrectas o errores de sintaxis. |
| 4 | Etiquetas canónicas | Comprueba que estas etiquetas se refieren correctamente a la URL canónica. |
| 6 | Páginas huérfanas | Encuentra páginas sin enlaces entrantes y crea enlaces internos. |
| 7 | Contenido robado | Comprueba si webs externas utilizan tu contenido. Crea etiquetas canónicas y evita URLs relativas. |
| 8 | Enlaces nofollow internos | Busca etiquetas nofollow en tu web y eliminalas. Las alternativas son las etiquetas canónicas o las etiquetas noindex |
| 9 | XML-Sitemap | Comprueba si tu sitemap contiene todas las URL que deben indexarse y comprueba los códigos de estado de las URL. |
| 10 | Hacking | Busca avisos sobre páginas pirateadas en la Google Search Console y, por ejemplo, cambia tus datos de acceso. |
Comprueba la indexabilidad de tu web con Ryte FREE
Escrito el 13.08.2018 por Clara Rubio.

Clara es una apasionada del mundo digital y la tecnología. Desde siempre ha estado interesada en en estos campos, llevándolos por bandera en su vida profesional y personal. Como redactora, escribirá sobre numerosos temas, incluyendo las novedades del mundo SEO y de cómo Ryte te ayudará en tu camino al éxito digital.