
Hace casi tres meses para celebrar “Halloween” al mejor estilo SEO decidí compartir en Twitter algunas historias de “horror” del día a día SEO con el hashtag “#SEOhorrorstories”.
Pronto el hashtag “#SEOhorrorstories” se convirtió en trending topic cuando cientos de SEOs alrededor del mundo comenzaron a compartir sus historias no sólo en Inglés, sino también en Español, Alemán y Francés, participando hasta Matt Cutts y la cuenta oficial de Google Analytics –puedes ver un poco más en este post que hice posteriormente comentando sobre la participación-.
Sin embargo, lo más curioso para mí es que muchísimas de estas historias que compartían casos “extremos” de problemas SEO –y aunque algunas se enfocaban claramente al humor-, es que se caracterizaban por ser:
Por ello me gustaría retomar las historias de “horror SEO” más comunes –con situaciones que también yo misma me he encontrado frecuentemente-, compartir sus diferentes escenarios y comentar cómo se pueden prevenir para que así las evitemos en la medida de lo posible - no está mal como propósito SEO para el 2016 :D -:
El bloqueo del acceso a los buscadores se puede dar en escenarios totalmente diferentes: Ya sea a propósito para intentar evitar una sobre-carga del servidor:

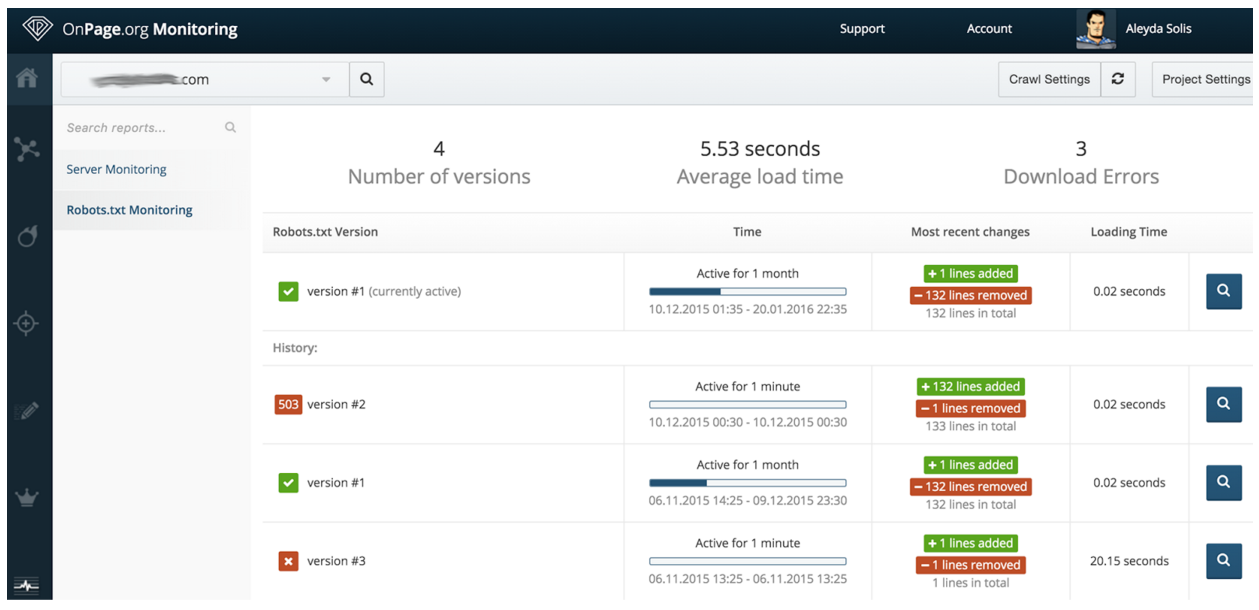
O por error a nivel del robots.txt al lanzar una Web a producción olvidando eliminar el bloqueo:

Lo cierto es que se puede evitar en gran medida usando un sistema de monitorización como el que ofrece OnPage con la funcionalidad de “Monitoring”, que alerta no sólo de los cambios en el robots.txt, sino además a nivel de caídas a nivel de servidor que te llegan directamente a través de correo electrónico también.
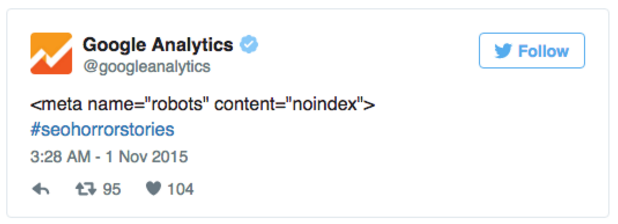
La desindexación errónea de sitios se da especialmente después de un rediseño o migración, durante la que suele olvidarse de modificar la etiqueta meta robots para permitir la indexación del sitio; sin embargo esto puede ocurrir también en cualquier momento, al actualizarse la Web:

Es fundamental monitorizar los cambios de los elementos críticos del código (así como del contenido) de las páginas del sitio con herramientas como Versionista, OnWebChange o NetWatcher que nos alertarán y permitirán ver los cambios que se generan en las mismas.
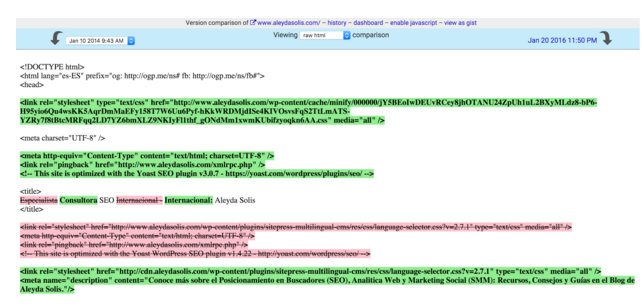

Una de las primeras preguntas que se deben hacer al comenzar el proceso SEO es sobre dónde se ubica el entorno de pruebas o preproducción, no sólo para saber si se podrán validar los cambios antes de lanzarse (que debería de ser lo ideal), sino además para asegurar que no está accesible a los buscadores.
El entorno de pruebas se debe bloquear no sólo a través del robots.txt sino además sólo permitiendo su acceso con contraseña o sólo mostrándose a través de determinados DNS.

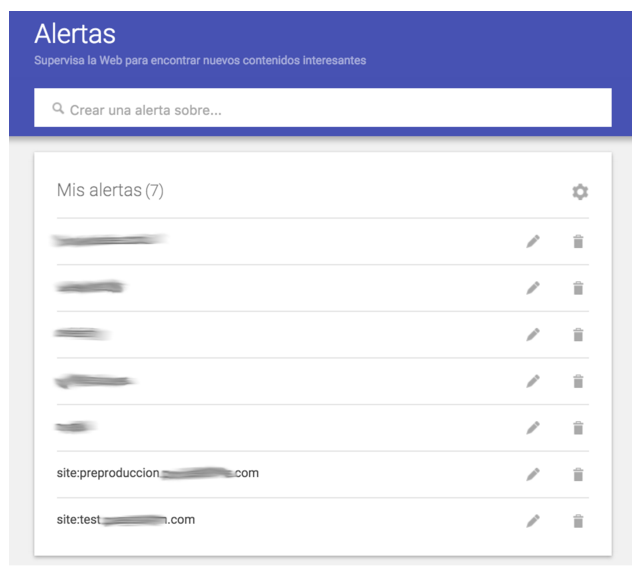
Ya que la configuración se puede modificar por error, además de la monitorización de los robots.txt configuro alertas con Google Alerts de un “site:” del (usualmente) subdominio de testeo o pre-producción y así ser notificada en caso que se identifique la indexación de contenido en el mismo:

Es muy común encontrar Webs que no están redirigiendo o canonicalizando a su versión original, lo cual suele identificarse al momento de hacer la auditoría SEO inicial, cuando se verifica si existe un problema de duplicación de contenido interno en la Web.
Sin embargo, la realidad es que cambios y actualizaciones continuas del sitio pueden generar esta problemática en cualquier momento.
Usualmente los rastreadores SEO facilitan esta validación ofreciendo un informe directamente listando las páginas con el contenido duplicado:
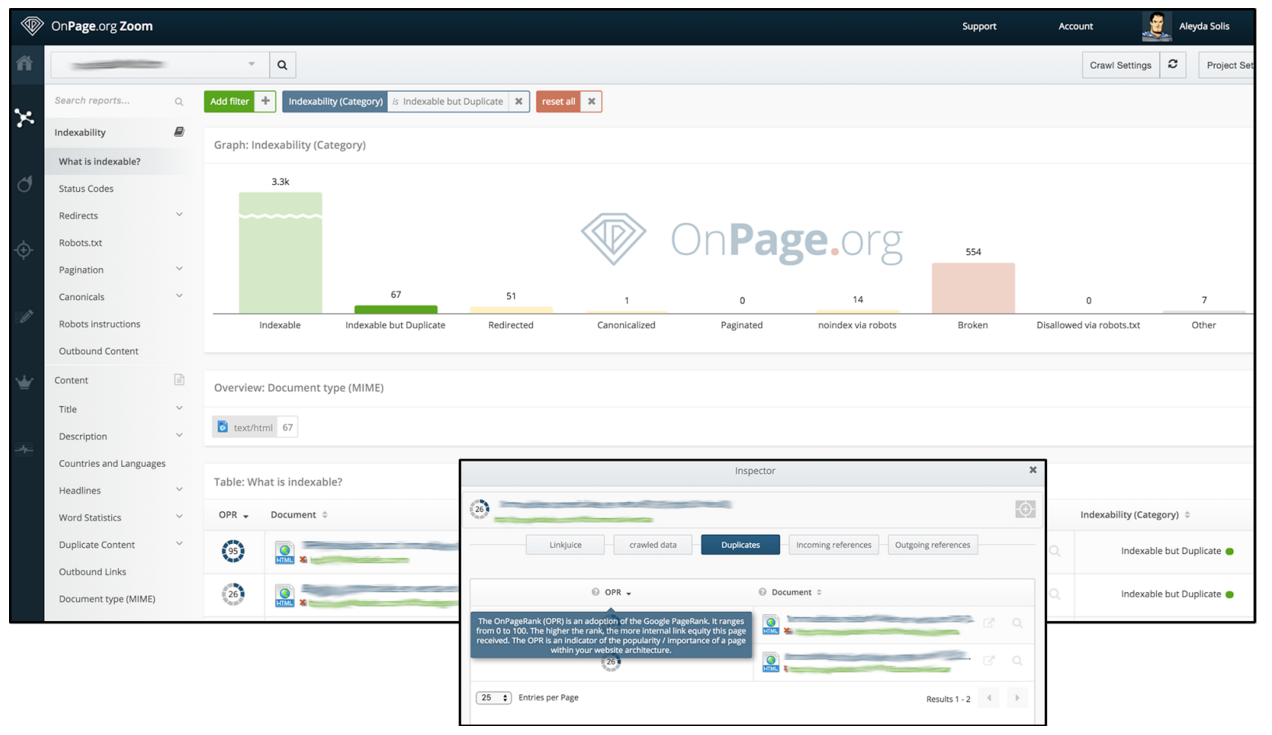
Por lo que es fundamental dejar programadas estas validaciones de forma frecuente para evitar que modificaciones de las que no se nos haya alertado generen nuevamente duplicación de contenido.
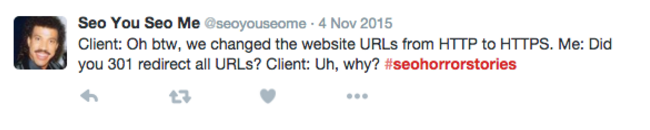
Esto puede ocurrir, por ejemplo, al migrar de http a https, sin que te hayan notificado:
O al publicar directamente el mismo contenido en varias páginas sin que tú lo sepas:

Para ello se pueden dejar programados rastreos frecuentes –funcionalidad ofrecida por la mayoría de rastreadores SEO como OnPage Zoom-, para que una vez se haya iniciado el proceso de posicionamiento se verifique recurrentemente que no vuelve a generarse contenido duplicado interno:
Este es uno de los escenarios que generan duplicación de contenido, pero es tan común –y representa toda una problemática en sí misma que también tiene otras consecuencias- que se merece un punto aparte y se puede resumir en estos dos tweets:

Y no sólo olvidarse o pasar de implementar redirecciones 301 de las direcciones antiguas a las nuevas –referenciando cada página a su nueva versión-, sino además de actualizar los enlaces, los XML sitemaps, de dar de alta el nuevo sitio en Google Search Console o de notificar el cambio de dominio en Google Search Console, entre otros pasos que el propio Google especifica con una guía de buenas prácticas para migraciones.
Siguiendo un plan de acción que debe iniciar antes del lanzamiento, al momento de planificar la migración Web, y no sólo al momento y después de lanzar.
Además de las buenas prácticas de Google, aquí tienes una serie de recursos y guías para una migración Web amigable al SEO y evitar perder todo tu tráfico orgánico y posicionamiento:
Al igual que ocurre con el bloqueo o desindexación errónea, los problemas con las redirecciones son usuales al rediseñar las Webs y no sólo por olvidarse migrar de la versión de las URLs antiguas a las nuevas, sino por hacerlo de forma no relevante.
Por ejemplo, redirigiendo masivamente al usuario (y robots de búsqueda) móviles a la versión de escritorio del sitio:

Redirigiendo hacia páginas de errores:

Redirigiendo en cadena no sólo con redirecciones permanentes 301, sino con cadenas de redirecciones temporales 302, que no pasan la popularidad de la página antigua a la nueva:

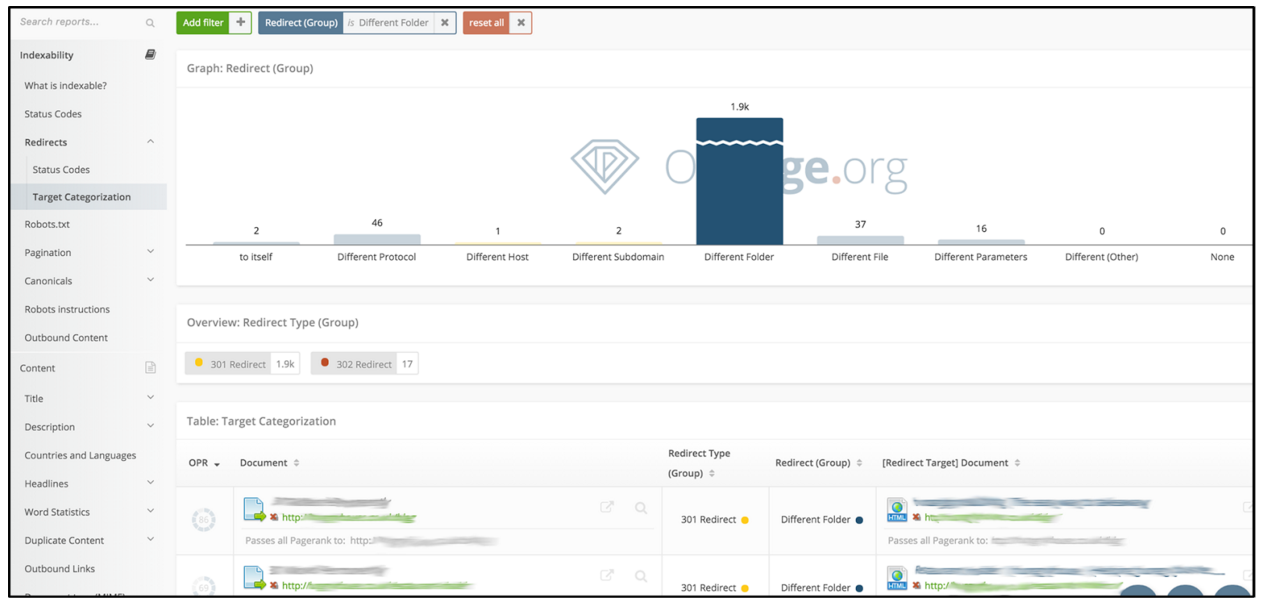
De forma similar a problemas anteriores, este tipo de problemas con las redirecciones son usualmente identificados y solventados al momento de hacer una auditoría técnica al inicio del proceso SEO, usando un rastreador como en este caso OnPage, que nos muestra directamente el tipo de redirecciones y a qué URLs dirigen:
Adicionalmente, en Google Search Console podemos identificar las redirecciones no relevantes que son marcadas como “Errores 404 Leves”, las páginas que se redirigen por ejemplo a aquellas que dan error, se encontrarían en el apartado de “No se Encuentra”, las que se redirigen a páginas bloqueadas en “Acceso Denegado” y las que se redirigen usando 302 en “URLs no seguidas”, dentro del informe de “Errores de rastreo”.
Lo más importante es no olvidar nuevamente verificar esta configuración frecuentemente con rastreos y validaciones recurrentes; así como solventar no sólo las incidencias identificadas sino lo que las causa o genera este problema en redirecciones.
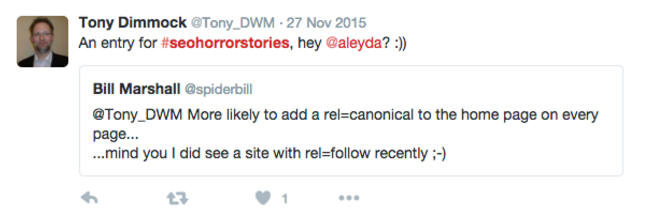
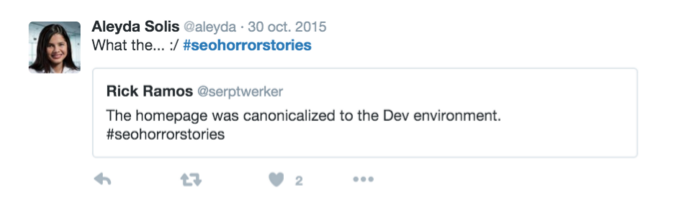
Algo similar ocurre con la canonicalización errónea, cuando las etiquetas canónicas apuntan a páginas que realmente no son la versión original de las mismas, lo cual puede suceder en escenarios muy diversos:
Cuando todas las páginas del sitio apuntan con su etiqueta canónica hacia una misma URL, por ejemplo, la página de inicio:
Cuando en vez de incluir el dominio del sitio se incluyen las IPs:

Cuando se mantienen las etiquetas canónicas en las páginas de un sitio recién lanzado apuntando hacia las páginas con las URLs de preproducción:
O cuando se lanza una versión internacional de la Web en un nuevo ccTLD que canonicaliza hacia el gTLD inicial:

Los problemas en la configuración de las etiquetas canónicas usualmente también se identifica al momento de hacer la auditoría técnica con un rastreador SEO en el que podremos fácilmente identificar cuáles son las páginas canonicalizadas (que no están apuntando hacia ellas mismas) y a qué URLs apuntan para verificar si realmente son la versión original, si contienen errores, si apuntan a otra Web, o a otras URLs que no son relevantes, etc:
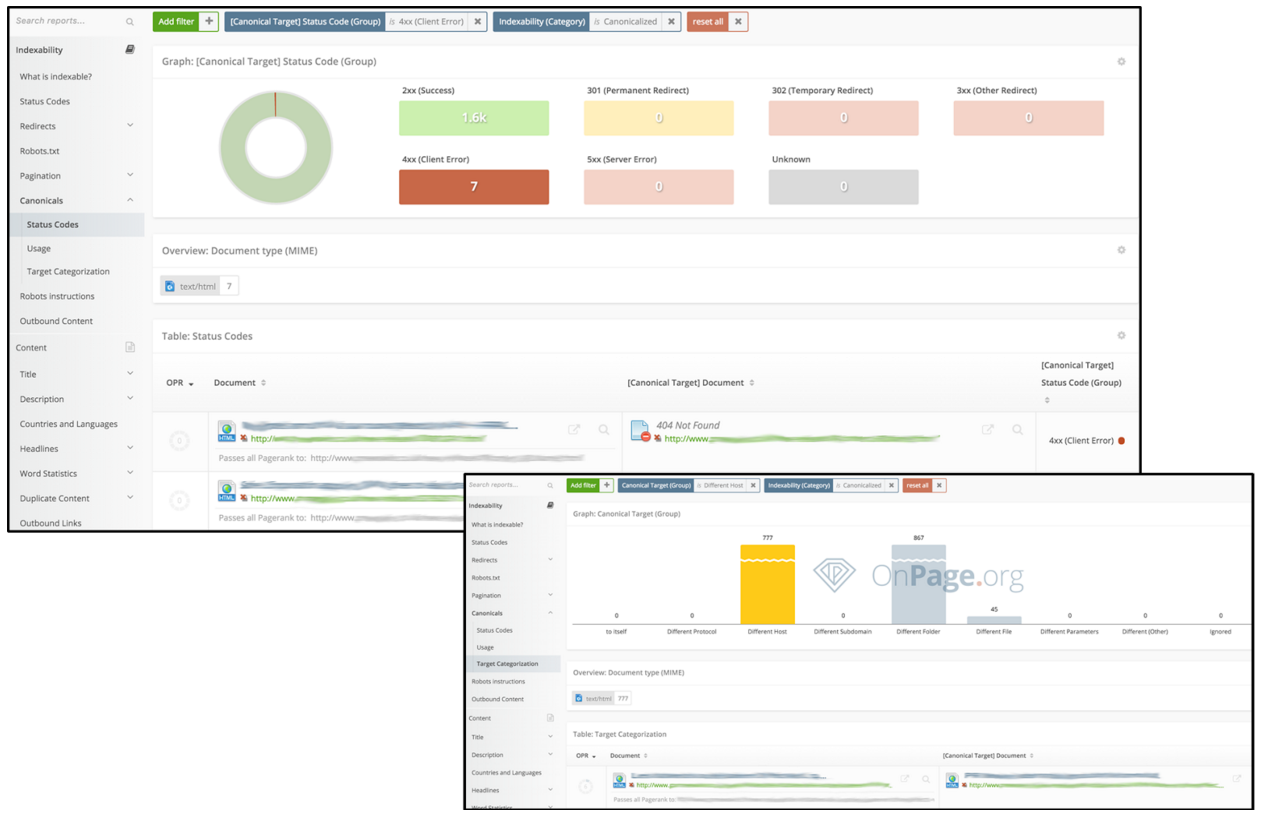
Y de igual forma, debe ser validada de forma recurrente dejando programados rastreos recurrentes que deben verificarse.
La ocultación de contenido como “técnica” de cloaking es un “clásico” (de lo no recomendado ya que va en contra de las directrices de Google, claro), sin embargo sigue usándose algunas veces a propósito –otras veces no-, para mostrar contenido diferente al buscador que al usuario:

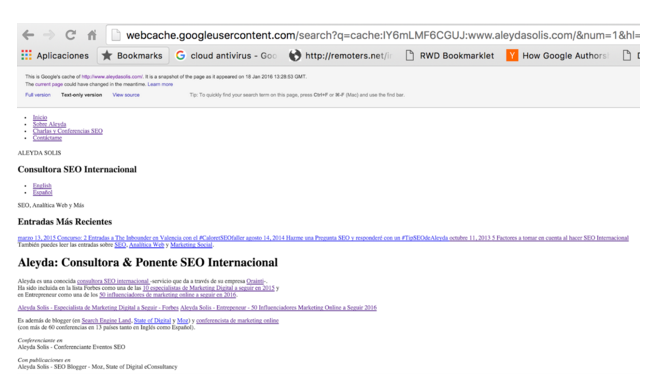
Por más fundamental que pueda parecer es indispensable siempre verificar (sobre todo al inicio de un proceso SEO con una Web nueva) cómo se indexa el contenido de las páginas y lo que se muestra en el propio caché del buscador en la versión de texto:
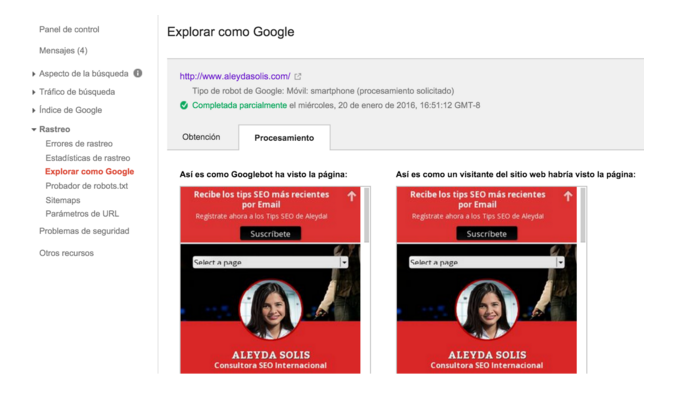
Así como usando la funcionalidad de “Explorer como Google” de Google Search Console para verificar diferencias potenciales en el contenido y diseño del sitio:
Una vez puesto en marcha el proceso, al monitorizar los cambios en el contenido y HTML de las páginas como se comentó anteriormente en el punto 2, podremos estar al tanto de cambios potenciales que ocurran en el código o contenido de las páginas, enfocados en este caso a ocultarlo y hacer cloaking.
Hacer uso de un CDN puede ayudar mucho a mejorar la velocidad de tu Web, sin embargo, sin una correcta configuración se puede correr el riesgo de ya sea: que se lleguen a indexar las copias del contenido del sitio habilitado usualmente en subdominios para el CDN, y por otro, que al bloquearse el rastreo totalmente de estos subdominios se bloquee también el acceso a archivos que se distribuyen a través del CDN que deben ser accesibles para los buscadores, como las imágenes, JS & CSS, ya que en caso contrario no podrá renderizar correctamente tu página.

La forma más fácil de evitar este problema es hacer uso de las opciones de configuración que los CDNs ofrecen usualmente enfocados al SEO y que permiten añadir un canonical header a los archivos que se “duplican” a través de los distintos subdominios del CDN para que apunten a sus URLs originales.
Con esto debería de bastar, pero adicionalmente, si se desea evitar el rastreo del contenido de estos subdominios dejando únicamente habilitado el mismo para los archivos estáticos como imágenes, JS & CSS –que son los que usualmente se sirven en los CDNs-, puede hacerse también con el uso de robots.txt personalizados para los mismos de forma alternativa.
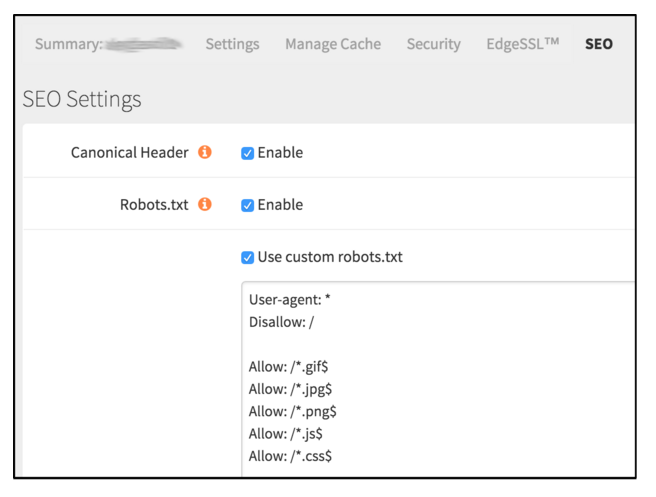
Para verificar que el Googlebot puede acceder correctamente al contenido y archivos de tu Web puedes hacer uso de la funcionalidad de “explorar como Google” en Google Search Console.
Google anunció hace algunos meses que dejaba de recomendar la propuesta que había hecho para el rastreo de sitios basados en AJAX hace unos años ya que ahora puede interpretar y procesar el Javascript, por lo que ahora recomienda seguir los principios de la mejora progresiva.
Lo cierto, es que aunque Google tenga una mayor capacidad de interpretar el Javascript no significa que no debemos hacer nada ya que nos podríamos encontrar con el HTML sin contenido:
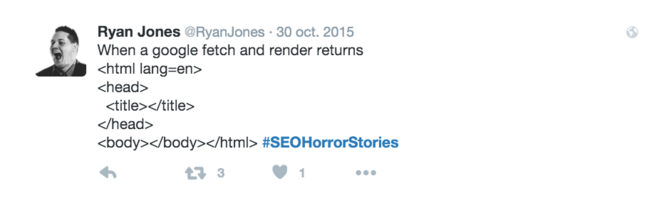
Para evitar encontrarnos en esta situación es recomendable, para elementos críticos de nuestra Web, como la navegación y áreas con contenido importante a rastrearse e indexarse que siempre se implemente directamente en el HTML y no se dependan de scripts.
En el caso que se usen frameworks de javascript como AngularJS se recomienda generar “snapshots” de las páginas usando Phantom.js o puedes usar servicios como el de Prerender.io. Echa un vistazo a este post de BuiltVisible donde comentan más sobre su implementación paso a paso.

Si, pueden ser muy divertidos si no te ocurren a ti, pero lo mejor es definitivamente evitarlos. ¡A por un año 2016 sin historias de Horrores SEO!
Escrito el 25.01.2016 por Aleyda Solis.

Aleyda Solis es Consultora SEO reconocida a nivel internacional y, a través de su empresa Orainti, ayuda a los sitios web a aumentar la visibilidad en los motores de búsqueda, el tráfico y el ROI. Aparece en Forbes entre los primeros 10 empresarios a los que seguir en 2015. Aleyda cuenta con más de 8 años de experiencia en SEO, especializada en consultoría de proyectos a nivel internacional, para todos los dispositivos. Además, participa en conferencias de Marketing Online por todo el mundo.